문자 집합과 인코딩
- 문자 집합(character set): 컴퓨터가 이해할 수 있는 문자의 모음. 문자 집합에 속해 있지 않은 문자는 컴퓨터가 이해할 수 없다.
- 인코딩(encoding): 코드화하는 과정. 문자를 0과 1로 이루어진 문자 코드로 변환하는 과정. 사람의 언어를 컴퓨터 언어로.
- 디코딩(decoding): 코드를 해석하는 과정. 0과 1로 표현된 문자 코드로 문자를 변환하는 과정.컴퓨터 언어를 사람의 언어로.
아스키 코드
- 가장 대표적이고 대중적인 문자 집합 그리고 인코딩 방법 중 하나로 초창기 문자 집합 중 하나이다.
- 알파벳과 아라비아 숫자, 일부 특수문자와 제어문자
- 7비트로 하나의 아스키 문자를 표현할 수 있다. 실제로는 아스키 코드 문자 하나를 표현하는데 8비트가 쓰이는데, 나머지 1비트는 패리티 비트(parity bit) 오류 검출을 위해서 사용되는 어떤 특수한 비트.
- 아스키 코드로 표현할 수 있는 총 문자의 개수는 2의 7승 개 즉 128개 정도의 문자.
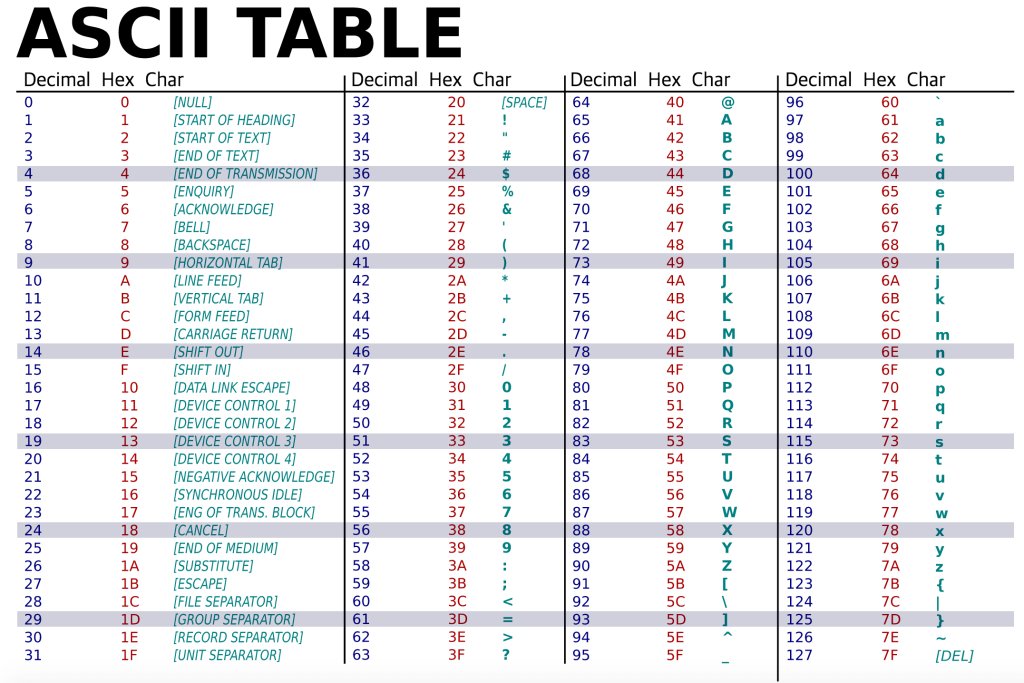
- 문자 하나 하나에 부여된 값들을 코드 포인트라고 한다.
- 인코딩 방식 자체는 간단하다는 장점 하지만 7비트로 문자를 표현하기 때문에 128개보다 많은 문자를 표현할 수 없다. 즉, 한국어, 중국어, 일본어 등 다양한 문자를 표현할 수 없는 글자들의 제한이 생긴다.
- 그래서 언어별 인코딩 방식이 등장한다.
한글 인코딩: 완성형 vs. 조합형 인코딩
- 한글 인코딩 방식에 대해서 이해하려면 한글의 특징에 대해서 이해해야 한다.
- 영어는 알파벳을 쭉 이어쓰기만 하면 단어가 되는 반면 한글은 자음과 모음의 조합으로 즉, 초성, 중성, 중성의 조합으로 하나의 단어가 만들어진다.
- 한글을 인코딩하는 것에는 크게 두 가지 방법이 있다. 완성형 인코딩 방식과 조합형 인코딩 방식.
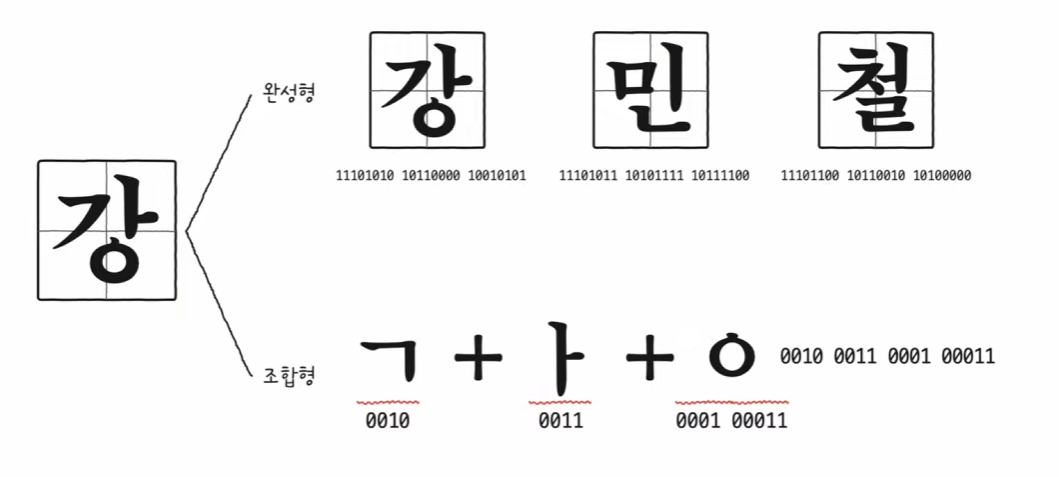
- 완성형 인코딩: 초성, 중성, 종성 자음과 모음의 결합으로 만들어진 단어 하나 하나의 코드를 부여하는 방식
- 조합형 인코딩: 초성, 중성, 중성에 해당하는 자음과 모음에 고유한 코드를 부여하는 방식
EUC-KR

- 'Extended Unix Code'의 약자로, 유닉스(Unix) 시스템에서 아시아 언어를 지원하기 위해 만들어진 인코딩 체계
- 한글과 한자 지원: EUC-KR은 한글과 한자를 포함한 2350자 이상의 한국어 문자를 표현할 수 있다. 이는 대부분의 현대 한국어 텍스트를 컴퓨터 상에서 다룰 수 있게 해준다.
- 2바이트 체계: 대부분의 한글 문자는 2바이트(16비트)로 인코딩된다. 첫 번째 바이트는 '가'부터 '힣'까지의 한글 자모를 나타내고, 두 번째 바이트는 조합된 한글 음절을 나타낸다.
- 확장성: EUC-KR은 KS X 1001 표준을 기반으로 하며, 이는 한국 산업 표준을 따르는 문자 집합이다. 특히 1990년대와 2000년대 초반에 많이 사용되었다.
- 한정된 문자 집합: EUC-KR은 한글과 한자에 대한 지원이 상대적으로 제한적이다. 모든 한글과 한자를 포함하지 않으며, 특히 다양한 외국어나 특수 기호를 표현하는 데는 한계가 있다.
- 프로그램 개발 상의 문제: EUC-KR은 한국어를 위한 인코딩 방식이기 때문에 한국어 처리에는 적합하지만, 다른 언어를 처리할 때는 적합하지 않다. 만약 여러 나라의 언어를 지원하는 프로그램을 만들려고 한다면, 각 언어에 맞는 인코딩 방식을 모두 이해하고, 프로그램에 적용해야 한다는 단점이 있다.
유니코드 문자 집합
- 유니코드는 전 세계의 모든 문자를 일관되고 통합된 방식으로 표현하기 위해 만들어진 국제 표준 인코딩 체계다.
- 범용성: 유니코드는 세계의 거의 모든 문자 시스템을 포함한다. 이는 라틴 알파벳, 키릴 문자, 아랍 문자, 한글, 한자, 힌디어, 태국어 등 수천 가지 언어와 기호를 포함하는 문자 집합이다.
- 일관된 인코딩: 유니코드는 각 문자에 고유한 코드 포인트를 할당한다. 예를 들어, 영문 대문자 'A'는 **U+0041**로, 한글 '가'는 **U+AC00**로 표현된다. 'U+' 뒤에 오는 16진수 숫자가 그 문자의 고유한 주소 역할을 한다.
- 다양한 인코딩 형식: 유니코드는 UTF-8, UTF-16, UTF-32 등 여러 가지 인코딩 형식을 제공한다. UTF-8은 가장 널리 사용되는 인코딩 방식으로, 1바이트에서 4바이트까지 가변 길이로 문자를 표현할 수 있다. 이는 영문자와 같은 일부 문자에 대해 효율적인 저장을 가능하게 하면서도, 전 세계의 모든 문자를 지원할 수 있는 유연성을 제공한다.
- 상호 운용성: 유니코드는 다양한 시스템과 플랫폼에서 호환된다. 이는 소프트웨어 개발자가 다양한 언어와 환경에서 작동하는 애플리케이션을 만들 수 있게 해준다.
- 확장성: 유니코드는 새로운 문자가 발견되거나 만들어질 때 이를 추가할 수 있는 충분한 공간을 가지고 있다. 이는 고대 문자나 아직 만들어지지 않은 기호에도 대비할 수 있음을 의미한다.
utf-8

utf-8 인코딩 방식에서 각 문자는 1바이트에서 최대 4바이트까지 다양한 길이로 인코딩될 수 있다. 이렇게 가변 길이로 인코딩하는 이유는 효율성과 호환성 때문이다. 예를 들어, 영문 알파벳과 같은 기본 라틴 문자는 많은 텍스트 문서에서 자주 사용되므로, 이들을 1바이트로 표현하면 저장 공간을 절약할 수 있다. 반면, 한글이나 한자와 같은 복잡한 문자는 더 많은 정보를 담기 위해 더 많은 바이트가 필요하다.
utf-8이 가변 길이 인코딩을 구현하는 방식은 매우 독창적인데, 각 바이트의 첫 몇 비트를 사용하여 해당 바이트가 문자의 어느 부분을 나타내는지를 알려주는 '표식'을 둔다.
- 1바이트 문자: 첫 비트가 **0**으로 시작한다. 이것은 ASCII 코드와 동일하며, 이로 인해 UTF-8은 기존의 ASCII 텍스트와 완벽하게 호환.
- 2바이트 문자: 첫 바이트는 **110**으로 시작하고, 두 번째 바이트는 **10**으로 시작한다. 이 두 바이트가 결합하여 하나의 문자를 나타낸다.
- 3바이트 문자: 첫 바이트는 **1110**으로 시작하고, 다음 두 바이트는 각각 **10**으로 시작한다. 이 세 바이트가 결합하여 하나의 문자를 나타낸다. 예를 들어 한글 '가'는 이 방식을 사용한다.
- 4바이트 문자: 첫 바이트는 **11110**으로 시작하고, 다음 세 바이트는 각각 **10**으로 시작한다. 이 네 바이트가 결합하여 매우 드문 문자나 이모티콘과 같은 특수 문자를 나타낸다.
이러한 '표식'은 UTF-8 인코딩이 문자의 길이를 동적으로 결정할 수 있게 해주며, 문자열을 읽는 시스템이 어디서 문자가 시작하고 끝나는지를 정확히 알 수 있게 해준다.
'컴퓨터구조와 운영체제' 카테고리의 다른 글
| 6. 명령어의 구조와 주소 지정 방식 (0) | 2023.11.06 |
|---|---|
| 5. 소스 코드와 명령어 (0) | 2023.11.06 |
| 3. 0과 1로 숫자를 표현하는 방법 (0) | 2023.11.03 |
| 2. 컴퓨터 구조의 큰 그림(2) (1) | 2023.11.02 |
| 1. 컴퓨터 구조의 큰 그림(1) (1) | 2023.11.02 |