명령어의 구조
‘무엇을 대상으로, 무엇을 수행하라’

컴퓨터 명령어는 일반적으로 두 가지 주요 구성 요소로 이루어져 있다: 연산 코드(opcode)와 오퍼랜드(operand). 연산 코드는 ‘무엇을 수행하라’를 담고 있고 오퍼랜드는 연산에 사용될 데이터 혹은 연산에 사용될 데이터가 저장된 위치를 오퍼랜드라고 한다. 특히 연산에 사용될 데이터가 저장된 위치를 훨씬 더 자주 저장한다. 이런 점에서 오퍼랜드가 담기는 그 공간 즉 오퍼랜드 필드를 주소 필드라고 부르기도 한다.
- 연산 코드 (Opcode): 연산 코드는 수행할 연산의 종류를 지정한다. 즉, CPU에게 무슨 일을 해야 할지를 알려주는 부분이다. 예를 들어, 덧셈, 뺄셈, 데이터 이동, 비교 또는 분기 등의 기본적인 연산을 나타내서 명령어의 "동사"라고 볼 수 있다.
- 오퍼랜드 (Operand): 오퍼랜드는 연산에 사용될 데이터를 지정한다. 이는 연산 코드가 작업을 수행해야 하는 실제 값을 또는 값을 저장하고 있는 메모리 주소를 가리킬 수 있다. 오퍼랜드는 명령어에서 데이터에 해당하는 "목적어"나 "보어"라고 볼 수 있다. 오퍼랜드의 개수는 여러 개가 될 수 있고 하나도 없을 수 있다.

명령어의 예
간단한 덧셈 명령어
ADD 5, 3
이 명령어는 'ADD'라는 연산 코드를 가지며, 두 개의 오퍼랜드 '5'와 '3'을 가진다. 이 경우, CPU는 5와 3이라는 두 값을 더하는 연산을 수행한다.
컴퓨터 명령어는 더 복잡한 형태를 가질 수도 있다. 아래의 명령어는 메모리 주소에 데이터를 저장하는 명령어다.
MOV [0x01], 10
'0x01'은 메모리 주소를 나타내고, '10'은 해당 주소에 저장될 값이다. 'MOV' 연산 코드는 '이동(move)'을 의미하며, 즉 '10'이라는 값을 '0x01'이라는 주소에 '이동'하라는 명령이다.
연산 코드
연산 코드는 명령어가 수행할 연산을 담고 있다라고 했는데, CPU에 따라 연산 코드가 다르다. 하지만 공통적으로 가지고 있는 연산 코드의 종류에는 데이터 전송, 산술/논리 연산, 제어 흐름 변경, 입출력 제어 이 네 가지가 있다.
각 범주별로 대표적인 연산 코드의 종류를 살펴보면,
- 데이터 전송(Data Transfer)
- MOV: 한 레지스터에서 다른 레지스터로, 혹은 메모리에서 레지스터로 데이터를 이동.
- PUSH: 스택에 레지스터의 값을 푸시.
- POP: 스택에서 값을 팝하여 레지스터에 저장.
- LD (Load): 메모리에서 데이터를 레지스터로 로드.
- ST (Store): 레지스터의 데이터를 메모리에 저장.
- 산술/논리 연산(Arithmetic/Logical Operations)
- ADD: 두 피연산자를 더함.
- SUB: 한 피연산자에서 다른 피연산자를 뺌.
- MUL: 두 피연산자를 곱함.
- DIV: 한 피연산자를 다른 피연산자로 나눔.
- INC (Increment): 피연산자의 값을 하나 증가.
- DEC (Decrement): 피연산자의 값을 하나 감소.
- AND: 두 피연산자 간의 비트 AND 연산을 수행.
- OR: 두 피연산자 간의 비트 OR 연산을 수행.
- XOR: 두 피연산자 간의 비트 XOR 연산을 수행.
- NOT: 피연산자의 비트 NOT 연산(비트 반전)을 수행.
- 제어 흐름 변경(Control Flow)
- JMP (Jump): 프로그램의 실행 흐름을 지정된 주소로 바로 점프.
- CALL: 서브루틴을 호출하고 나중에 복귀할 주소를 스택에 저장.
- RET (Return): 서브루틴에서 복귀할 때 사용.
- JE/JZ (Jump if Equal/Jump if Zero): 조건에 따라 점프를 수행.
- JNE/JNZ (Jump if Not Equal/Jump if Not Zero): 조건에 따라 점프를 수행.
- JG/JL (Jump if Greater/Jump if Less): 조건에 따라 점프를 수행.
- 입출력 제어(I/O Control)
- IN: 특정 포트로부터 데이터를 읽어 레지스터에 저장.
- OUT: 레지스터의 데이터를 특정 포트로 전송.
오퍼랜드
오퍼랜드에는 연산에 사용될 데이터 혹은 연산에 사용될 데이터가 저장된 위치가 저장된다. 그런데 연산에 사용될 데이터가 저장된 위치가 더 많이 저장된다. 그렇기 때문에 오퍼랜드가 담기는 이 공간 오퍼랜드 필드를 주소 필드라고 부르기도 한다. 오퍼랜드 필드에는 레지스터 주소가 담길 수도 있고 메모리 주소가 담길 수 있고 연상 코드에 사용될 데이터가 직접적으로 명시될 수도 있다. 그런데 그냥 데이터를 직접 넣으면 되지 왜 굳이 위치를 쓰는 걸까? 명령어 내에서 표현할 수 있는 데이터의 크기가 제한되기 때문이다.

유효 주소: 연산에 사용될 데이터가 저장된 위치. 만약 연산에 사용될 데이터가 1이라고 하는 레지스터에 저장되어 있다면 유효 주소는 1 레지스터

명령어 주소 지정 방식
명령어 주소 지정 방식(Instruction Addressing Modes)은 CPU가 명령어의 오퍼랜드를 어떻게 해석하고 접근하는지에 대한 방법을 정의한다. 다시 말해, 명령어에서 데이터를 어디에서 가져오고 결과를 어디에 저장할지, 즉, CPU가 명령어를 해석하고 데이터를 찾아가는 방법을 정의를 결정하는 방식이다.
즉시 주소 지정 방식 (Immediate Addressing):

- 데이터가 명령어 자체에 포함되어 있다. 가장 간단한 형태의 주소 지정 방식이다.
- 메모리 접근이 필요 없어 빠른 실행이 가능하다.
- 데이터 크기가 명령어 길이에 제한 받기 때문에 연산에 될 데이터의 크기가 제한될 수 있다.
직접 주소 지정 방식 (Direct Addressing):

- 명령어가 메모리 주소를 직접 포함한다. 즉, 오퍼랜드 필드의 유효 주소를 직접적으로 명시하는 방법이다.
- 주소를 나타낼 수 있는 범위에 제한이 있다 (주소 길이에 의해).
- 주소 길이에 의해 접근할 수 있는 메모리 범위가 제한된다.
간접 주소 지정 방식 (Indirect Addressing):
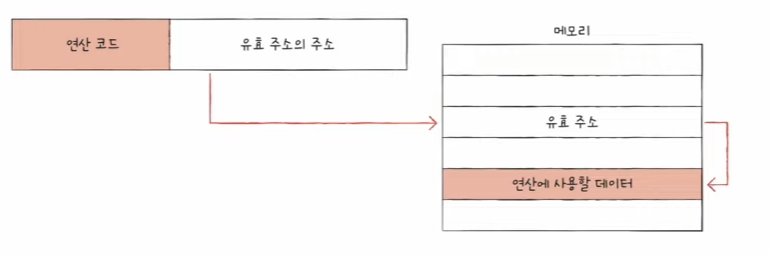
- 앞선 문제를 극복하기 위한 방법 중에 하나이다.
- 명령어가 유효 주소를 가리키는 포인터를 포함한다.
- 실제 데이터 주소를 얻기 위해 여러 단계의 메모리 접근이 필요하다.
- 메모리 접근 횟수 증가로 속도 저하가 발생할 수 있다.
레지스터 주소 지정 방식 (Register Addressing):
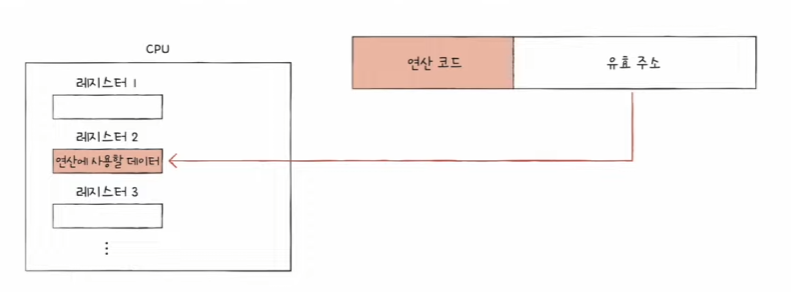
- 연산에 필요한 데이터가 레지스터에 저장되어 있다.
- 메모리 접근보다 빠른 실행이 가능하다.
- 메모리 대신 레지스터를 직접 사용한다는 특징이 있다.
레지스터 간접 주소 지정 방식 (Register Indirect Addressing):
- 연산 데이터의 주소가 레지스터에 저장되어 있고 레지스터가 실제 데이터의 메모리 주소를 간접적으로 가리킨다.
이 외에도 다양한 주소 지정 방식들이 존재한다.
'컴퓨터구조와 운영체제' 카테고리의 다른 글
| 8. CPU의 내부 구성 - 레지스터 (0) | 2023.11.07 |
|---|---|
| 7. ALU와 제어장치 (0) | 2023.11.07 |
| 5. 소스 코드와 명령어 (0) | 2023.11.06 |
| 4. 0과 1로 문자를 표현하는 방법 (0) | 2023.11.03 |
| 3. 0과 1로 숫자를 표현하는 방법 (0) | 2023.11.03 |